Automated Tweets with AWS Lambda and DynamoDB
Another article about Amazon Web Services (AWS), this time creating a Lambda (or Serverless or Function as a Service) which tweets about this very blog at regular intervals, using DynamoDB as its data store. I also use AWS Simple Notification Service (SNS) to trigger an e-mail to let me know the tweet has happened.
As an added bonus, there is also a refresher on functional programming in Javascript, and Javascript promises.
If you want to follow along, the code is available at ianfinch/blog-tweet
High-Level Approach
The general approach is to use DynamoDB to store a list of tweet templates, which we will select at random for each tweet. We also use DynamoDB to record the tweets we have sent (which we can use to track interactions later). Finally, we send a notification to SNS which allows us to send an e-mail (via an SNS subscription).
As with all credentials, it is important that we don’t put them in the code — I don’t want someone finding my Twitter access details in Github. So, I also use DynamoDB to store my Twitter credentials
This means that our high-level approach consists of the following steps:
- Get list of blog tweet templates
- Get history of blog tweets
- Choose random template, weighted so least tweeted is most likely
- Get Twitter credentials
- Tweet template + link to blog post
- Update tweet history to reflect this new tweet
- Use SNS to send e-mail notification
Setting up DynamoDB
I used the AWS online console to set up my DynamoDB tables. First select
DynamoDB from the services menu and click on the create table option. In
the dialog which opens, I chose blog-tweet-templates as the table name, and
tweet-id (of type String) as the partition key (note that you will have
to make sure you have sufficient permissions enable within AWS to allow this):
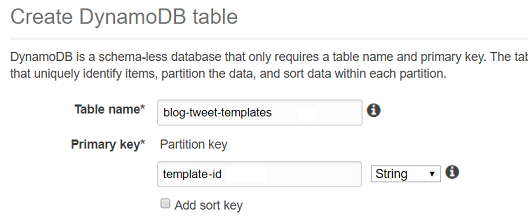
This will happen fairly quickly and then you will see a page showing the create item button:
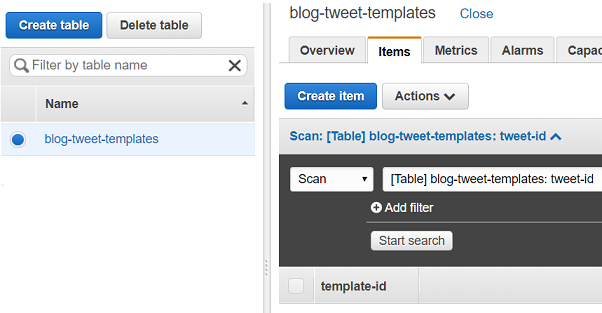
Clicking on this button, you will be presented with a dialog allowing you to
enter data. You will see only the partition key (template-id in our
example) in the dialog. DynamoDB is schemaless, meaning we don’t need to
define our fields upfront — we can add whatever fields we like in any record.
For my templates, I created a field called slug, which will contain the slug
of the article (for later tracking) and a field called message, which
contains the text to go into the tweet:
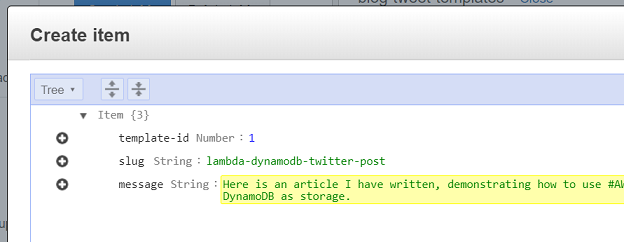
When this is saved, you can see it in the items area in the web console. Here it is, with some other tweet templates added:
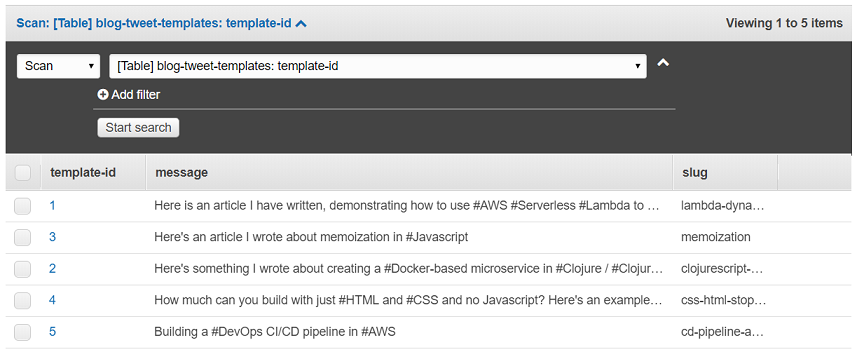
I then repeated the table creation step, to create a table with the name
blog-tweet-history and a partition key of tweet-id. I didn’t create any
items in this table, because it will be populated by the Lambda.
Finally, I created a third table called blog-tweet-keys, which will contain
the access keys needed for the Lambda to post to Twitter. For a full solution,
we need to apply encryption to these, but that is the subject of a whole
separate article. For this table, I set the partition key to be user, which
will take the Twitter user ID the Lambda will post as (and allows me to develop
it in the future, to support multiple accounts).
To get the credentials to store in this table, you will need to go to apps.twitter.com and create an application. This is a simple web form, with a few fields to complete, then you will be presented with the access tokens you need.
Once I got these credentials, I added them to my credentials table, with the following fields:
- access-secret
- access-token
- consumer-key
- consumer-secret
Which gave me the following:

I now have all the tables set up that I will need, so let’s start on the code side of things.
The package.json File
AWS Lambda has an online code editing box, which is fine for creating simple Lambdas, but this code has to do a fair amount and also needs to include an external module to interact with Twitter. For these reasons, I used the upload code to Lambda option instead. This means I needed to write the code locally, then zip it up and upload the zip file to AWS.
Our life is simpler if we use a package.json file, so here is the one I used:
{
"name": "lambda-blog-post",
"version": "1.0.0",
"description": "Lambda function to send tweet for a blog post",
"main": "run.js",
"dependencies": {
"aws-sdk": "^2.149.0",
"twit": "^2.2.9"
},
"devDependencies": {},
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"author": "Ian Finch",
"license": "ISC"
}
As you can see, it’s very simple — I only need the AWS SDK and the Twit module as dependencies, and I am going to create a run.js file which I can use from the command line, while I am developing the code.
Running Our Lambda Code from the Command Line
I want my actual code for the Lambda to be the same whether it’s running within the AWS Lambda service, or whether I run it from the command line. I will therefore write a small wrapper (called run.js) which I can call from the command line, this will require my actual Lambda code which can then be identical both locally and within AWS.
As well as requiring our module (which I’ve imaginatively called lambda.js), the run.js wrapper needs to provide a callback function (which our Lambda code can invoke) and needs to actually trigger the code. The code will be exported as a function called handler from our lambda.js file.
As Javascript code, it looks like this:
var lambda = require("./lambda.js");
function callbackHandler(err, success) {
if (err) {
console.error(err);
} else {
console.info(success);
}
}
lambda.handler(null, null, callbackHandler);
The other thing I needed to do, was to download my credentials from AWS and put
them in a file at ~/.aws/credentials. The AWS SDK automatically finds them
and gives my code access to my AWS services.
Includes and Declarations
For completeness, I’ll just show the includes and declarations I use:
var Twit = require("twit");
var AWS = require("aws-sdk");
AWS.config.update({region: 'us-east-1'});
var docClient = new AWS.DynamoDB.DocumentClient();
var sns = new AWS.SNS();
var blogServer = "https://ian-says.com/";
var snsTopic = "arn:aws:sns:us-east-1:XXXXXXXXXXXX:blog-tweeted";
We need the Twit and AWS modules as discussed earlier. I also found that I needed to set the region explicitly in the code. Then I instantiate a docClient to interact with DynamoDB and an sns object. I also define the base URL for my blog (to be used when constructing links) and the SNS Topic I will be sending notifications too.
Our Handler Function
Luckily, Amazon added promises to the NodeJS SDK in a recent update, and the Twit module also supports promises. This means we can avoid callback spaghetti and structure our handler in a clean way. If you’re not familiar with promises in Javascript, you can check out my handy guide to promises in Javascript for an introduction.
So, our handler code is pretty much a straight copy of the steps in the high-level approach described earlier:
function handler () {
getTemplates()
.then(getHistory(null))
.then(getTwitterCredentials)
.then(sendTweet)
.then(updateHistory)
.then(sendToSns)
.then(successMessage)
.catch(errorHandler);
}
I’ll explain the getHistory(null) expression later.
Note the .catch() at the end of all the .then() calls. This will catch any
error generated through any of the .then() calls and pass it to our error
handler. This means I don’t need to handle errors separately for each step —
another advantage of using promises over callbacks.
Unfortunately, we need to do a bit more than just writing that function. As I said, lambda.js is a Javascript module and the handler is exported from that module in the standard way. This means we can’t just use that function as is, we need to use the exports mechanism. I also want an error handler and a success message mechanism, which will depend on the callback I mentioned earlier. Since the callback is passed to the handler, the error and success handlers also need to be within that scope to get access to the callback.
This means we modify our handler function to become:
exports.handler = (event, context, callback) => {
function errorHandler(err) {
console.error(err);
callback("Error tweeting about blog");
}
function successMessage(data) {
console.info(data);
callback(null, "Tweeted about blog: " + data.slug);
}
getTemplates()
.then(getHistory(null))
.then(getTwitterCredentials)
.then(sendTweet)
.then(updateHistory)
.then(sendToSns)
.then(successMessage)
.catch(errorHandler);
};
Get the Templates
DynamoDB provides a few ways to retrieve data, intended for different situations, with differing levels of efficiency. Because I want to get all the available tweet templates (so I can randomly select one), I will use the scan operation. This is the least efficient operation — since it scans all the entries in the table — but since that’s exactly the behaviour I want, that’s not a problem.
So, the first thing I need to do is set up the parameters for my DynamoDB scan. The important thing is obviously that I need to provide the table name:
function getTemplates(soFar) {
var templateTable = {
Limit: 3,
TableName: "blog-tweet-templates"
};
...
So, a couple of obvious questions are: “what is that soFar variable for?” and “what is that Limit statement for?”.
Well, a DynamoDB scan might not return all the entries in a table in one go. We may have to repeatedly call it, getting a chunk at a time. The soFar parameter allows me to repeatedly invoke this function, passing through the entries retrieved so far (see what I did?) and adding new entries to them (similar to a reduce function). The Limit statement is to deliberately force a small number of entries to be returned with each scan operation, to ensure I exercise the soFar part of the code.
Having cleared that up, let’s move on to the next part of the function. As you will remember from the handler code, we don’t initially pass in a soFar value. We will therefore check for its absence, to detect the first call to this function. Then, for that first call, we will initiate our scan:
...
if (!soFar) {
return docClient.scan(templateTable).promise()
.then(getTemplates([]));
}
...
As you can see, we indicate to that AWS SDK that we want a promise, by adding a
call to the promise() function to our scan. This is the consistent way to
get promises across the entire AWS SDK. Since we have a promise, we can use a
then() to handle the (asynchronous) response. We use the then to
recursively pass the response back to this function. Since this will be the
first time, we have performed a scan, you can see that our soFar parameter is
an empty array.
Let’s dig into this code a bit more before we move on, and break down the
expression .then(getTemplates([])). We know that .then() takes a function
as a parameter, so getTemplates([]) needs to be a function that returns a
function — so the function returned from getTemplates() is actually the
parameter for .then(), not getTemplates() itself. There are a lot of
examples of this pattern in my guide to functional programming in
Javascript.
So, given that getTemplates() has to return a function to receive a resolved
promise, we can now look at the remainder of the function. If we get this far,
we know we have a value in soFar and we also know that we need to return a
function which will handle the result of the DynamoDB scan.
So, our returned function will receive the result of the DynamoDB scan in its
parameter (which I have called data). The actual entries from the table are
in an element of that called Items, so we iterate over data.Items adding
each tweet template to our soFar array (which is available within the
function because we have a closure:
function getTemplates(soFar) {
...
return function (data) {
var allItems = soFar;
data.Items.forEach(function (item) {
item.tweeted = 0;
allItems[item["template-id"]] = item;
});
...
Note that we also initialise a tweeted value to zero. We will increase this count later, when we read from our history table.
If our DynamoDB scan has more entries left to read, our data structure will
have a LastEvaluatedKey defined. So, if it is defined, we then initiate a
new scan, using that LastEvaluatedKey as the point at which to start it. We
pass the allItems array we’ve just built up into the recursive call to
getTemplates(), to enable us to keep aggregating any further items. Note
that we are building up a chain of promises which
will be traversed as the scans resolve:
...
if (typeof data.LastEvaluatedKey != "undefined") {
templateTable.ExclusiveStartKey = data.LastEvaluatedKey;
return docClient.scan(templateTable).promise()
.then(getTemplates(allItems));
}
...
Finally, if we have read the last (or only) entries, we can return allItems as our final result. Because we want to chain this in our handler, we need to wrap that result in a promise:
...
return Promise.resolve(allItems);
};
}
So, that was quite a detailed discussion of the getTemplates() function. To
summarise — it initiates the first scan, aggregates successive scans via a
promise chain, then returns a promise containing all the scanned entries.
We’re now going to use a similar approach for the getHistory() function,
which we can cover in much less detail.
Get the History
If you recall, way back in this article when I discussed the handler
function, we passed null into getHistory(). Now we can see why we did this
— we use it to differentiate between the first call to getHistory() and
subsequent calls.
Just like getTemplates(), we have two basic scenarios — initiate the first
scan, and handle the result of that and subsequent scans. The main difference
is that happens after getTemplates(), so always needs to return a function.
The other difference, is that the soFar we pass in will be the templates we
got from getTemplates(). As we read records from the history table, we
increment the counts for the template (based on template-id) within the
templates array, and keep passing that via the soFar parameter.
So, here’s the start of the function and the initial call:
function getHistory(soFar) {
var historyTable = {
TableName: "blog-tweet-history"
};
if (soFar === null) {
return function (templates) {
return docClient.scan(historyTable).promise()
.then(getHistory(templates));
};
}
...
And here’s the rest of the function, which receives the result of the scan, and uses it to increment the tweeted count in the templates array. It also sets up subsequent scans, just like we did for the templates table:
...
return function (data) {
var enriched = soFar;
data.Items.forEach(function (item) {
enriched[item["template-id"]].tweeted += 1;
});
if (typeof data.LastEvaluatedKey != "undefined") {
historyTable.ExclusiveStartKey = data.LastEvaluatedKey;
return docClient.scan(historyTable).promise()
.then(getHistory(enriched));
}
// If there are no more items, select a random tweet and return it
return Promise.resolve(randomTweet(enriched));
};
}
Note that we don’t return the whole array of tweets in our promise, we call a
randomTweet() function to choose one. Now we will look at that function.
Choose a Random Tweet Template
So, now we have an array of all the tweet templates, including a count of how many times they’ve been tweeted. Now I want to choose one of these at random. However, I want to weight this random selection, so that templates which have been tweeted less are more likely to be selected. The way I decided to do this was to build up an array which repeats each template inversely proportional to the number of times it has been tweeted, then randomly choose an element of that array.
Here’s the code that implements the above approach:
function randomTweet(tweets) {
// Find the total of all the tweeted counts
var total = tweets.map(function (tweet) {
return tweet.tweeted;
}).reduce(function (sum, val) {
return sum + val;
}, 0);
// Edge case for empty table (total = 0), set it to 1
if (total === 0) {
total = 1;
}
// Assign weights based on occurrences
var weights = tweets.map(function (tweet) {
return {
"template": tweet["template-id"],
"weight": (total - tweet.tweeted) / total
};
});
// Build up an array based on weighting
var selection = [];
weights.forEach(function (tweet) {
var n;
for (n = 0; n < Math.floor(100 * tweet.weight); n++) {
selection.push(tweet.template);
}
});
// Select a random element of that array
return tweets[selection[Math.floor(Math.random() * selection.length)]];
}
Get Twitter Credentials
Now we have chosen a tweet, we need to retrieve our credentials to allow us to tweet. We already set up the credentials table earlier, so we just need to retrieve it from DynamoDB.
Because we have a key we can search on (the twitter username), we don’t need to use scan, we can use the more efficient get. The code is much simpler than the previous examples, we just set up our parameters, invoke get, and set up a function to handle the result:
function getTwitterCredentials(tweet) {
var credentialsTable = {
TableName: "blog-tweet-keys",
Key: {
user: "ianf"
}
};
return docClient.get(credentialsTable).promise()
.then(processTwitterCredentials(tweet));
}
Note that we are still in a chain of .then() calls, and we can only pass one
parameter between each call. However, we want both the tweet we selected
earlier, plus the credentials we retrieve from DynamoDB. To achieve this, we
once again use a closure to persist the tweet within the
processTwitterCredentials() function, then add the data from the
credentials query:
function processTwitterCredentials(tweet) {
return function (data) {
return Promise.resolve({
tweet: tweet,
credentials: data.Item
});
};
}
Send the Tweet
Now we have credentials and a tweet, it is simple to actually send the tweet. The Twit module has a post function which allows us to do this:
function sendTweet(data) {
var twitter = new Twit({
consumer_key: data.credentials["consumer-key"],
consumer_secret: data.credentials["consumer-secret"],
access_token: data.credentials["access-token"],
access_token_secret: data.credentials["access-secret"]
});
return twitter.post("statuses/update",
{ status: data.tweet.message + " " + blogServer +
"articles/" + data.tweet.slug + "/" })
.then(processSentTweet(data.tweet));
}
The post function returns a promise, which contains all the data returned from the tweet operation (such as the id of the tweet which was sent). So we need a function to handle the result of the tweet operation. Because we also want the details of the tweet template we used (so we can update the history table), we use the same closure technique we used for credentials to add the template to the result of the tweet operation:
function processSentTweet(template) {
return function(data) {
data.template = template;
return Promise.resolve(data);
};
}
So, we have now successfully sent our tweet and we have details of both the tweet details and the template, ready to be passed on to the next step in our handler — updating the history table.
Update the History Table
To update our history table, we use the same basic pattern as before — create
a params structure, then pass it to the docClient. This time we use the
put() function to create a new item. Our history table uas the tweet-id
as the primary key, so we use the id passed back from our tweet in the
previous step (since it is reasonable to assume that Twitter is using a
unique ID for their tweets).
The code is therefore very simple:
function updateHistory(tweet) {
var params = {
TableName: "blog-tweet-history",
Item: {
"template-id": tweet.template["template-id"],
"tweet-id": tweet.data.id_str,
message: tweet.data.text,
slug: tweet.template.slug,
user: tweet.data.user.screen_name,
"user-id": tweet.data.user.id_str,
date: tweet.data.created_at
}
};
return docClient.put(params).promise()
.then(function () { return Promise.resolve(params.Item); });
}
The only point to note is that we need to work around a strange omission in the
AWS SDK. The DynamoDB functions for updating the database allow you to specify
various different return options (for example, the record that was updated or
the record that was replaced by an updatae), but the put() function doesn’t
return the record that you created. This is why our then() function creates
a new promise, based on our parameters structure. I put that function inline,
since it is so simple.
We now only have one thing left to do — send a notification, to trigger an e-mail.
Send SNS Notification
I took a simplistic approach to the SNS notification. I just put all the data from the previous step into the message, and set a subject based on the blog item that was selected:
function sendToSns(data) {
var params = {
Message: JSON.stringify(data),
Subject: "Tweeted about blog: " + data.slug,
TopicArn: snsTopic
};
return sns.publish(params).promise()
.then(confirmSnsPublication(data));
}
I don’t really need to confirm the SNS publication (the catch() function will
be triggered if there are any errors), but I am using it to log the result of
this final step. These will appear in the AWS log files, in case I need them:
function confirmSnsPublication(tweet) {
return function (data) {
console.log("TWEET", tweet);
console.log("DATA", data);
return Promise.resolve(tweet);
};
}
So, there we have all the code. And I can test that it works, by running it from the command line:
node run.js
I can verify that it works, by looking at the console output:
TWEET { 'template-id': 3,
'tweet-id': '9XXXXXXXXXXXXXXXX4',
message: 'Here\'s an article I wrote about memoization in #Javascript https://...............',
slug: 'memoization',
user: 'ianf',
'user-id': '5XXXXX2',
date: 'Mon Nov 20 21:46:58 +0000 2017' }
DATA { ResponseMetadata: { RequestId: '0XXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXX5' },
MessageId: 'XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXX3' }
{ 'template-id': 3,
'tweet-id': '9XXXXXXXXXXXXXXXX4',
message: 'Here\'s an article I wrote about memoization in #Javascript https://...............',
slug: 'memoization',
user: 'ianf',
'user-id': '5XXXXX2',
date: 'Mon Nov 20 21:46:58 +0000 2017' }
Tweeted about blog: memoization
I can also check that a new record has been created in my DynamoDB history table:

I should have received an e-mail:
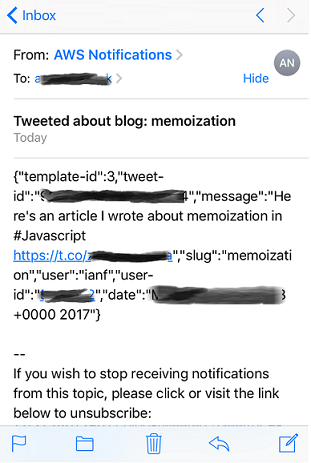
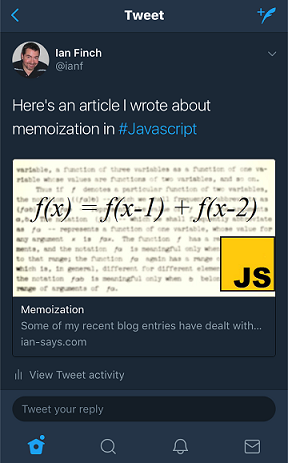
And most obviously, I should be able to see the tweet (perhaps I should have put that first in this list):
Deploying the Lambda to AWS
So, now we have a working script from the command line, we can now create our Lambda itself. You can check my previous AWS deployment pipeline article for a more in-depth example of Lambda functions, but I will quickly go through this here.
We need to do three things:
- Bundle our code into a ZIP file
- Create a role in IAM to give our Lambda suitable permissions
- Create the Lambda, and upload our Zip file
Create a ZIP File
This is simple - I just need the lambda.js file, plus the node modules directory (keeping that structure). There’s nothing special about the ZIP file, so you can use any tool to create it:
You will note that I haven’t included run.js in here. This is because we
only need that file for testing from the command line.
Create a Role in IAM
As described in some of my previous previous aws articles, we first need to create an IAM Policy, then create an IAM Role and apply the policy to it. The policy needs to grant access to run a lambda, read and write from DynamoDB, and publish a notification to SNS.
The steps to create the policy, role and apply them are straightforward in IAM (or you can refer to my AWS deployment pipeline article for more detail).
I have used the policy editor this time, which is easier than editing raw JSON:
Create the Lambda
Go to the Lambda dashboard within AWS and click on create function, then click on author from scratch. This takes you to the following screen:
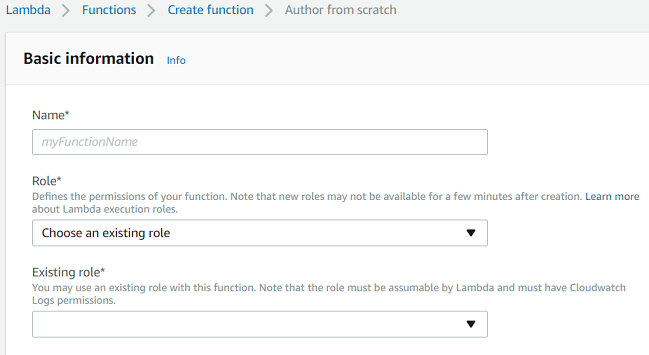
We now enter the name for the lambda, plus associate the role we created with it (and then click on create function):
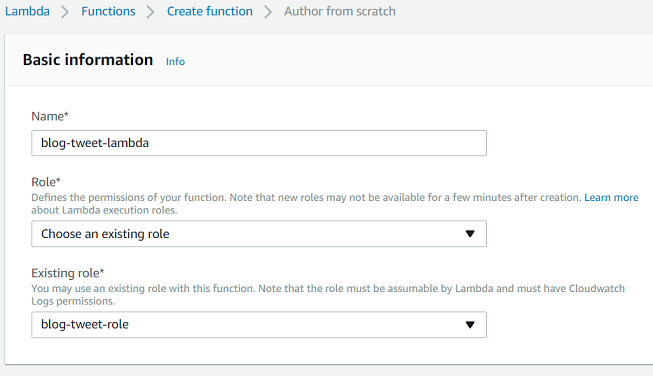
This takes us to the function editor, which by default looks like this:
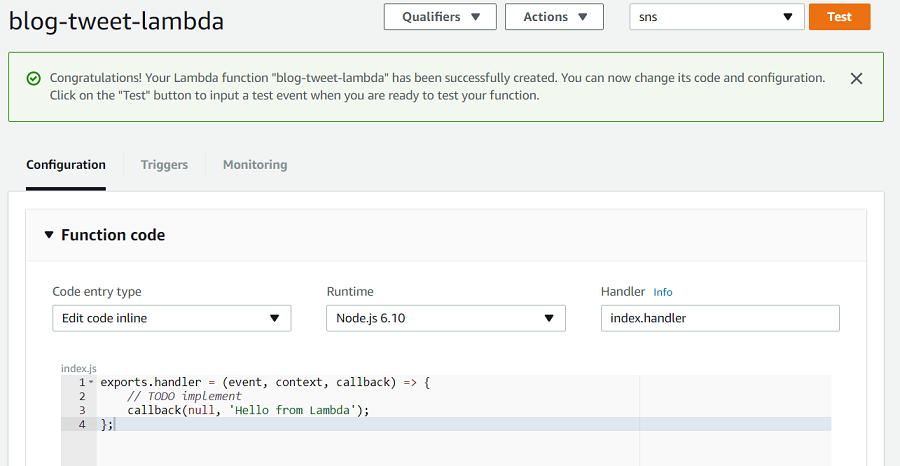
We now select that we will upload a ZIP file, check that our runtime is
NodeJS, and set our handler to be lambda.handler (because the name of our
file was lambda.js and the function we exported was called handler). We
also click on upload and select the ZIP file we just created:
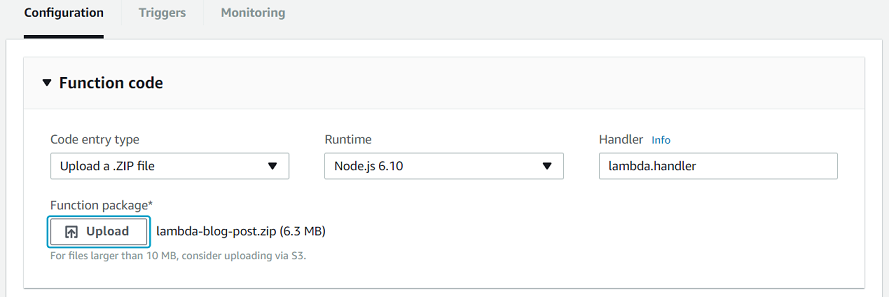
Then we scroll down the page and select the role we created earlier:
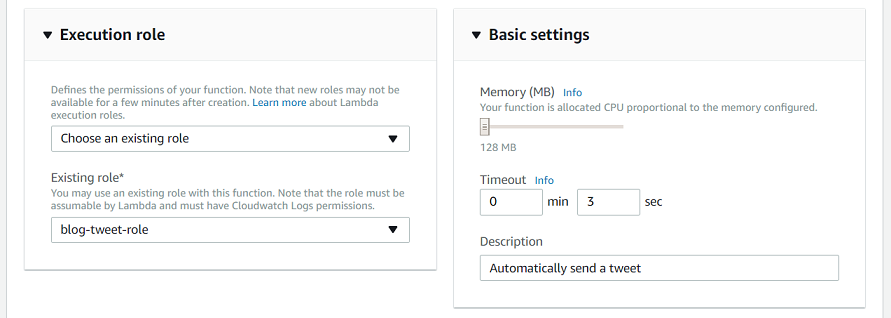
Now we can go back to the top of our page and test our Lambda by clicking on the Save and Test button (this can take a while the first time, since it needs to upload the ZIP file):

Then you can see the output of the lambda when the page refreshes — we expect it to work, since it already worked from the command line. If there’s a problem, it would most likely be that the lambda has not been granted sufficient privileges:
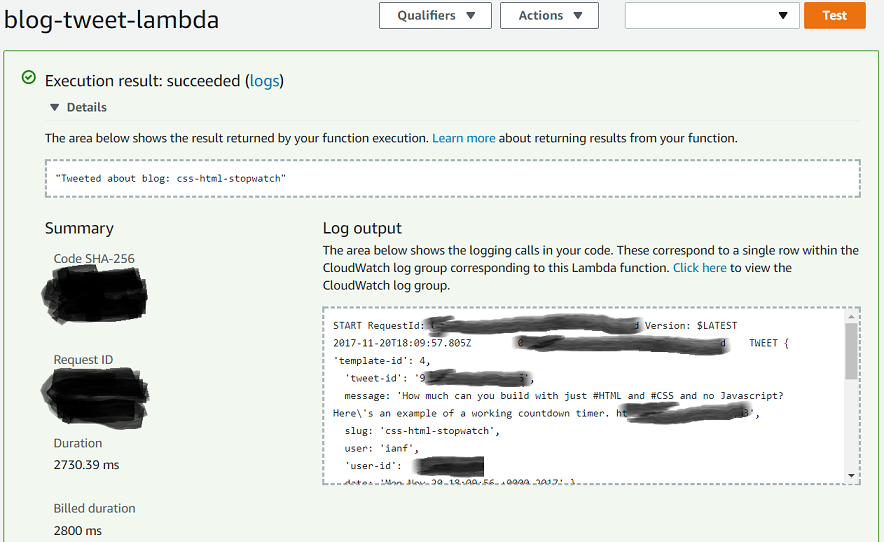
Looking at the result, you can see where the callback was invoked (the white box towards the top), and the log outputs (in the scrolling area on the right). Obviously, I can also look at Twitter to see if my tweet appears.
So we now have our working Lambda running in AWS. The only thing left is to run this on a regular basis, so that we send out a daily tweet.
Setting up a Daily Schedule
In order to set up a timed schedule, we need to use CloudWatch — the AWS monitoring tool. This can be configured to trigger an event when a certain threshold is reached, but can also trigger events on a timed basis (which is what we need). So, if I go to CloudWatch, click on events in the sidebar, and then click on Create Rule, I see the following:
So, now we select Schedule, set up our repeat (I’ve chosen 24 hours), and set the target as the Lambda we’ve just created, then we move on to configure details:

The details we add are just a name and description:
When we submit this page, it will first trigger the Lambda, and then schedule the next occurrence in 24 hours.
Summary
So, this article has showed how to use AWS Lambda and DynamoDB as the basis for sending out tweets at regular intervals. It has covered a range of technologies:
- DynamoDB — get, put and scan
- Lambda — package and upload code, run same code from the command line
- CloudWatch — as a mechanism for triggering Lambdas
- SNS — as a mechanism for triggering e-mails
- Promises in Javascript
- Propagating data through a promise chain
- Closures and functions that return functions