Breadth First Graph Traversal in Clojure (Kiwiland Example)
In my previous article, I looked at how to create a graph in Clojure, and find the length of various journeys within it. I will now move on to look at how to search the graph, to solve some of the other questions in the Kiwiland Trains Programming Challenge. This will focus primarily on the implementation of a breadth first search.
The Problem
Here is a quick reminder of the problem we are trying to solve. We have a graph, representing a railway, which looks like this:

Our task is to answer the following questions:
- The distance of the route A-B-C.
- The distance of the route A-D.
- The distance of the route A-D-C.
- The distance of the route A-E-B-C-D.
- The distance of the route A-E-D.
- The number of trips starting at C and ending at C with a maximum of 3 stops.
- The number of trips starting at A and ending at C with exactly 4 stops.
- The length of the shortest route (in terms of distance to travel) from A to C.
- The length of the shortest route (in terms of distance to travel) from B to B.
- The number of different routes from C to C with a distance of less than 30.
In my previous article, I answered the following questions:
- The distance of the route A-B-C.
- The distance of the route A-D.
- The distance of the route A-D-C.
- The distance of the route A-E-B-C-D.
- The distance of the route A-E-D.
This article is going to look at how to search through this graph, to answer questions where there are multiple possible answers. That will answer the following questions:
- The number of trips starting at C and ending at C with a maximum of 3 stops.
- The number of trips starting at A and ending at C with exactly 4 stops.
- The number of different routes from C to C with a distance of less than 30.
Before I get into actual code, I want to look at some search patterns, so I can decide the best design for the algorithm.
Search Strategies
Search strategies are all about how to move from node to node in the graph, in a way which provides the optimal solution for the problem we are trying to solve. Broadly speaking, we can take two approaches — depth first or breadth first. So let’s start by looking at them.
Depth First Search
To start looking at search strategies, it is easier to understand them using simpler structures first. The structure I’ll use is based on the train map, but I’ve removed any cycles from it, to give a tree data structure (in computer science terminology).
Here are a set of diagrams showing how depth first search works. In these diagrams, green represents an unvisited node, blue represents a visited node, and red is the node we are currently visiting:
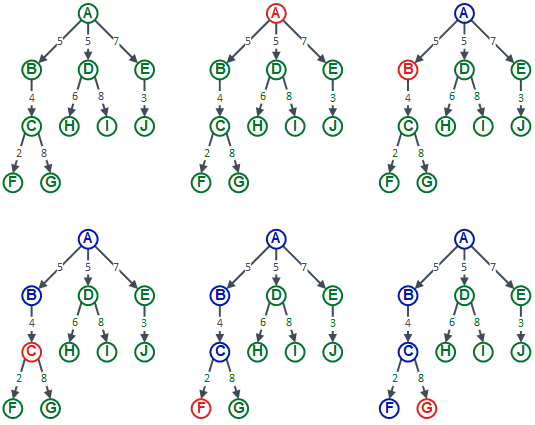
The first picture shows the tree with nothing visited. The second picture shows us visiting node A. We then look at the children of the current node, and visit the first of those. This is illustrated in the third picture, where we are visiting node B. We now look at the children of this current node, and visit the first of those, which takes us on to the fourth picture, where we are visiting node C. We repeat the process from node C, and visit its first child. This is shown in the fifth picture, where we are visiting node F. Node F has no children, so we go back to the children of node C and visit the next child, which is node G shown in picture 6.
I haven’t illustrated the rest of the traversal, but with no more nodes to visit after node G, we go back up to node A and start the process again with its next child (node D). This means we visit the remaining nodes in the order: D, H, I, E, J.
Depth first search is similar to the way a simple recursive function works. There are multiple factors to consider, which might lead us to choose the use of a depth first search. One typical problem that depth first search is used for, is when there is a single correct solution being looked for. Finding the path through a maze would be an example of that. If we know that the answer will be found on a leaf node (for example, finding a file in a directory structure), that would also be an indicator to use depth first search. If we know the tree is shallow, we would also probably use depth first search.
If the tree is very deep (or of undefined depth), we may choose not to use depth first search (or we may used a modified version with a maximum search depth).
Breadth First Search
Breadth first search traverses the tree by visiting all the children of a node, before moving onto the children of children. Here is a diagram which represents this strategy:
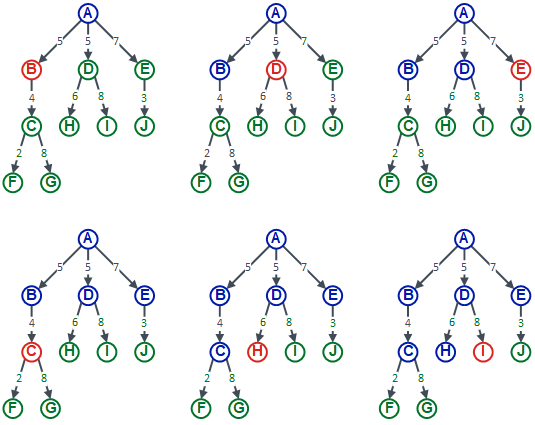
You can see that all the children of node A are visited before moving on. So, we start at A, then go to B, D, and E. Once we have exhausted all the children of node A, we then go down a level and visit the children of node B (i.e. node C). Then, because node B has no more children, we go to the next child of node A (i.e. node D) and visit its children — nodes H and I. We would then go on to visit nodes J, F, and G.
Breadth first search is useful where we are trying to collect sets of information, or where the tree may have large or indeterminate depth. In a social network, if you think of your relationships as a tree (your direct connections, your direct connections' connections, etc), you may want a list of all relationships of level 2 or level 3. Breadth first would be good for this.
It’s also useful, where we are looking for solutions close to our current location. Imagine you are driving with your Sat Nav, and you want to find the nearest petrol station. Breadth first would work well here, since it would look for petrol stations on your current road, then look for roads off your current road, then roads off those, etc.
Since the questions we are trying to answer are all about the number of trips (or routes), it feels like breadth first might be a better approach, but we’ve only looked at trees so far. Let’s make this look a bit more like our Train Map, by allowing multiple connections into nodes, and see what that does to our approach.
Searching an Acyclic Graph
In the tree data structure we were looking at, a node could have multiple connections coming out of it, but only one connection going into it. I’m now going to remove that constraint, and allow multiple connections into a node too. However, I am still going to keep the restriction that we can’t have any cycles in our graph. Technically, this is a directed acyclic graph. Here is an example of how we could search it, using a breadth first approach:
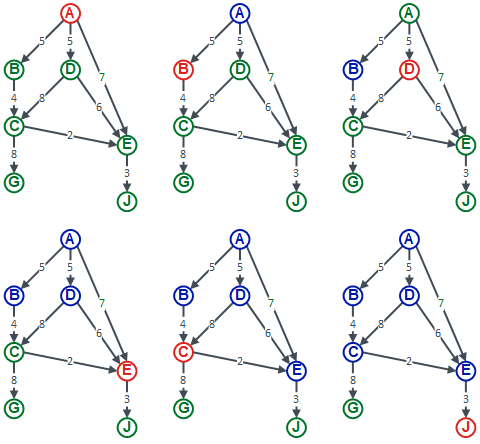
Although the layout is not so obvious as our tree was, the first four pictures are actually the same as for the tree. We visit node A, then visit its children, B, D, and E. The fifth picture is where things start to be a bit different. We go back to node B and look for its children. The only child is node C, so we visit that. Node B has no other children, so we move on to node D and look for its children. Its first child is node C, which we have just visited, and its second child is node E, which we have also already visited. That exhausts all the children of node D, so we move on to the children of node E (because it is the last child of node A). Node E has one child, which is node J, and the sixth picture shows that being visited. Finally, we visit the remaining node, which is G (not illustrated here).
Unlike a tree, with a directed acyclic graph, you can see that it is possible to visit a node multiple times. Usually, we only want to visit any node one time, so we mark nodes as already visited, so as to ignore them if they occur again.
Apart from this extra requirement to track already visited nodes, this is pretty much the same as traversing a tree. So, let’s also allow cycles, which will enable us to go back to our original train map.
Searching a Cyclic Graph
Now that we can have cycles in our graph, technically we just have a directed graph. I’ve changed the layout slightly in the pictures below, but it represents the same graph that I included at the start of this article:
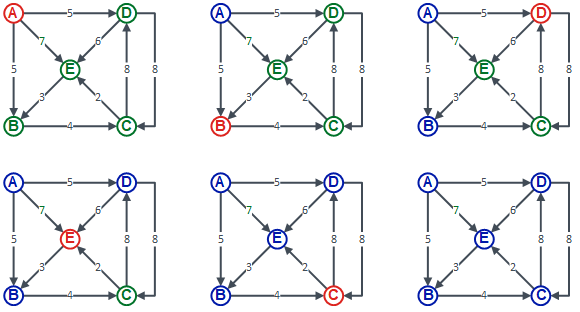
Since I’ve now stepped through several of these diagrams, I will just make brief notes here against each picture.
- Picture 1
- We are at the first node we will consider, node A.
- Picture 2
- We are keeping the same breadth first approach and order as before, so we move on to node B next.
- Picture 3
- Again, we follow the same pattern as before, so we visit node D as the next child of node A.
- Picture 4
- On to the next child of node A, which is node E.
- Picture 5
- Now that we have exhausted all the children of node A, we move to children of children. So, going to the first child of node A, which is node B, we find one child — node C. This, therefore, is the next node we visit.
- Picture 6
- We’ve now visited all the nodes in the graph, so we can finish … or can we?
For tree data structures and directed acyclic graphs, we will always have leaf nodes — i.e. nodes which have no children. This means that there is always a natural end to our search — we reach a point where there are no more child nodes to follow. Once we allow cycles, however, that is not always true. In our train example, every node has at least one outgoing connection. So, once I have visited node C, for example, I could carry on and visit node D again. Then from node D I could visit node C again, and I could keep looping round like that as many times as I like.
So we have two options:
- Impose a rule of only visiting any node once, and halting once all nodes are visited
- Allow nodes to be visited multiple times, and use some other way of stopping
Which approach is correct? As always, the answer is “it depends”. Does the
problem you are trying to solve (or the domain you are working in) require you
to visit a node multiple times? In our railway example, the answer is clearly
“yes”. If you go back and look at the
problem, you can see answers
which have multiple visits to the same station. For example, question 7 has A -> B -> C -> D -> C and A -> D -> C -> D -> C as correct answers.
This means we have to pick the second of our two options, which has a consequence that we need some new way of stopping the search.
Pruning a Search Space
The way we usually restrict a search tree (or search space) is called pruning, and involves removing parts of the search based on some criteria. This idea was used in Chess computers, for example, where there are so many possible moves that it is not possible to explore them all, so the search tree is pruned to remove the least promising areas. Another example is a Sat Nav or map application looking for restaurants. The search tree is potentially massive (every restaurant in the world), but the search is pruned by distance (or travel time) so it can present an answer quickly.
Since I have an infinite search tree (for example, a route could go between node C and node D as many times as it likes), I need to adopt a similar approach. This makes my breadth first search work in a two step way — first I have an expand step, where I add new nodes to my search, then I have a prune step, where I remove any parts of the search which are no longer relevant.
My Search Function Approach
So, I now have some principles I can construct my search function around:
- Use breadth first search
- Take an expand / prune approach
- Immutable data (principle adopted in previous article)
I don’t want to create an excessive number of test cases, so it’s also worth thinking about how I can cover as many examples as possible in one test. Covering the following would be a good start:
- A valid answer without a cycle, e.g.
A -> B -> C - A valid answer including a cycle, e.g.
A -> B -> A - A valid answer contained in another valid answer, e.g.
A -> BandA -> B -> C
Then I also want another test case, where no valid solutions exist (which I can base on the same graph). Here’s a simple test graph that meets the above conditions:
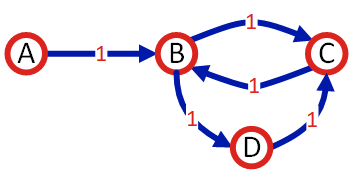
Then I can use the question “find all routes starting from A and ending at C,
with a length of less than 5”. A -> B -> C (length 2) is a solution without
a cycle, and A -> B -> C -> B -> C (length 4) is a solution with a cycle.
Furthermore, the second solution contains the first, which is the third part of
my test. For an impossible to find solution, I can look for all routes
starting from A and ending at C, with a length of 3.
I can also use this question to think about how I structure my search function. There are three parts to the question “starting from …", “ending at …", and “with a length of less than …". The first part is the starting node, the second is the condition for knowing a search is complete, and the third is how to prune the search — when the length reaches 5 or more, there is no point in searching further. So, my function will look like this:
(defn search
"Walk the graph using a breadth-first approach. A complete function is
supplied which is used to flag when journeys are complete. A prune condition
is also supplied, to remove any paths that should no longer be pursued."
[the-graph start-node complete? prune?]
...)
We’ve already talked about the expand then prune approach we will take, so
I’ll think about that next. I’ll assume for now that I’ve got an (expand ...) function, I will need to call that first:
(expand the-graph start-node)
Then apply the (prune? ...) function to the result:
(prune? (expand the-graph start-node))
Finally, I want to check if I’ve completed my search:
(complete? (prune? (expand the-graph start-node)))
Or using threading:
(-> the-graph
(expand start-node)
prune?
complete?)
Except the expand step will potentially return multiple possible answers, for
example if I am at node B, my (expand ...) will find both B -> C and B -> D. So I can’t apply the (prune? ...) function to the result, I need to
(map ...) it across a list of results. Doing this, and the same thing for
(complete? ...), I get:
(-> the-graph
(expand start-node)
(prune-paths prune?)
(check-complete complete?))
Putting this back into our function definition, I have this:
(defn search
[the-graph start-node complete? prune?]
(-> the-graph
(expand start-node)
(prune-paths prune?)
(check-complete complete?)))
Where I have supporting functions of the form:
(defn prune-paths
"Can we prune down our search space?"
[paths prune?]
(filter prune? paths))
(defn check-complete
"Check whether any journeys are complete, based on the completion test."
[paths complete?]
(map complete? paths))
Now I want to think about what the result of this looks like. I clearly need the steps in the journey I am following, I need some way of indicating that a journey is complete, and because the length of the journey is important I need to include that too. So, I will have a hash like this:
{:path [:A :B]
:complete? false
:distance 1}
So, let’s start coding up some of the above functions, beginning with (expand ...).
The Expand Function
The first thing to think about is the code organisation. I’m going to put all the search functionality into its own namespace, and then only import the search function into the graph. So, I need two new files, one for my tests:
(ns kiwiland.search-test
(:require [clojure.test :refer :all]
[kiwiland.search :refer :all]))
And one for my code:
(ns kiwiland.search)
I’m going to start slowly with a simple utility function, allowing me to add a
step to a path. For example, if I have an edge :B -> :C with length 2, and I
add it to an existing path [:A :B] of length 5, I will get a path [:A :B :C] of length 7. Expressed as a test, it looks like this:
(deftest added-step
(testing "Adding a step to a path"
(is (= (add-step [:A :B] :C 5 2)
{:path [:A :B :C] :distance 7}))))
I also want it to handle the situation where we have just a single node (with no distance). So I’ll also add a test for that:
(deftest add-first-step
(testing "Adding the first step to a node"
(is (= (add-step [:A] :B nil 1)
{:path [:A :B] :distance 1}))))
The code to satisfy these tests is:
(defn add-step
"Add a step to a path"
[existing-steps new-step existing-distance new-distance]
(hash-map :path (conj existing-steps new-step)
:distance (+ (or existing-distance 0) new-distance)))
Now that I can add a step to a path, let’s look at how to add all the possible
next steps from a path. Suppose we are using our test graph from earlier, and
we have a path so far of [:A :B]. There are two routes out of :B — to :C
or to :D. So, I would have two new paths as a result — [:A :B :C] and
[:A :B :D]. Both of these would have a distance of 2.
Using the representation of a path I arrived at earlier, that path so far would look like this:
{:path [:A :B]
:distance 1}
If you recall our representation of the graph as an adjacency list (flip back to my previous article if you need to). Using this representation, our test graph looks like this:
{:A {:B 1}
:B {:C 1 :D 1}
:C {:B 1}
:D {:C 1}}
Suppose the path is stored in a variable the-path and the graph is stored in
a variable the-graph, we need to find the last step in the-path (which
would be :B in this case):
(-> the-path
:path
last)
Then we need to find that node in the-graph:
(get the-graph (-> the-path
:path
last))
In our example, that would return this structure:
{:C 1 :D 1}
So we would then need to pass these into our (add-step ...) function:
(add-step [:A :B] :C 1 1)
(add-step [:A :B] :D 1 1)
We can use a (map ...) to do this:
(map #(add-step ... ) (get the-graph (-> the-path :path last)))
Or to make it more readable:
(let [next-steps (get the-graph (-> the-path :path last))]
(map #(add-step ... ) (keys next-steps))
Let’s add in the parameters for (add-step ...):
(let [next-steps (get the-graph (-> the-path :path last))]
(map #(add-step (:path the-path)
%
(:distance the-path)
(get next-steps %))
(keys next-steps)))
So, given a graph and a path, this lets us find all the paths following on from it. Let’s wrap it up as a function:
(defn add-next-steps
"Adds the possible next steps to a path"
[the-graph the-path]
(let [next-steps (get the-graph (-> the-path :path last))]
(map #(add-step (:path the-path) %
(:distance the-path) (get next-steps %))
(keys next-steps))))
I’ll define my test graph in my test file, so I can use it in multiple tests:
(def test-graph (graph/build-graph ["ab1" "bc1" "cb1" "bd1" "dc1"]))
Now I can write a test for this function:
(deftest check-next-steps
(testing "Find next steps in a path"
(is (= (add-next-steps test-graph {:path [:a :b] :distance 1})
[{:path [:a :b :c] :distance 2}
{:path [:a :b :d] :distance 2}]))))
Now I can build my (expand ...) function on top of this. It will need to
take a list of paths, and return the expanded list of paths. Basically, it
needs to map across the set of paths so far, passing each one into my
(add-next-steps ...) function:
(defn expand
"Expand a set of paths, by finding the next steps for each one"
[the-graph paths]
(map #(add-next-steps the-graph %) paths))
If I try this out in the REPL, I get the following output:
kiwiland.core=> (search/expand test-graph [{:path [:a]} {:path [:a :b] :distance 1}])
(({:path [:a :b], :distance 1}) ({:path [:a :b :c], :distance 2} {:path [:a :b :d], :distance 2}))
You can see here, that I’ve got lists inside lists. This is because the outer
list is from the (map ...) in my (expand ...) function, and the inner lists
are from the (map ...) in (add-next-steps ...), which is called from
(expand ...). What I really want is a flat list, but that’s easy to achieve,
by just adding a (flatten ...) call:
(defn expand
"Expand a set of paths, by finding the next steps for each one"
[the-graph paths]
(-> (map #(add-next-steps the-graph %) paths)
flatten))
Let’s add a test for this:
(deftest check-expand
(testing "Check expanding the set of search paths"
(is (= (expand test-graph [{:path [:a]} {:path [:a :b] :distance 1}])
[{:path [:a :b], :distance 1}
{:path [:a :b :c], :distance 2}
{:path [:a :b :d], :distance 2}]))))
A slight complication I need to add in, is for paths which are already complete. I don’t want to expand those (since they are already complete). This test illustrates the principle — one path is already complete and passes through unchanged, but the other does get expanded:
(deftest check-expand-with-complete
(testing "Check expand when some paths are complete"
(is (= (expand test-graph [{:path [:a :b :c] :distance 2 :complete? true}
{:path [:a :b :d] :distance 2}])
[{:path [:a :b :c] :distance 2 :complete? true}
{:path [:a :b :d :c] :distance 3}]))))
To cater for this situation, I need to add in a check to exclude completed paths:
(defn expand
"Expand a set of paths, by finding the next steps for each one"
[the-graph paths]
(-> (map #(cond (:complete? %) %
:else (add-next-steps the-graph %)) paths)
flatten))
And let’s check all our tests:
$ lein cloverage
Loading namespaces: (kiwiland.core kiwiland.graph kiwiland.search)
Test namespaces: (kiwiland.core-test kiwiland.graph-test kiwiland.search-test)
Loaded kiwiland.graph .
Loaded kiwiland.search .
Loaded kiwiland.core .
Instrumented namespaces.
Testing kiwiland.core-test
Testing kiwiland.graph-test
Skipping ab11 since it has more than 3 characters
Skipping 1ab could not parse: java.lang.NumberFormatException
Testing kiwiland.search-test
Ran 33 tests containing 33 assertions.
0 failures, 0 errors.
Ran tests.
Writing HTML report to: /usr/src/lein/target/coverage/index.html
|-----------------+---------+---------|
| Namespace | % Forms | % Lines |
|-----------------+---------+---------|
| kiwiland.core | 100.00 | 100.00 |
| kiwiland.graph | 100.00 | 100.00 |
| kiwiland.search | 100.00 | 100.00 |
|-----------------+---------+---------|
| ALL FILES | 100.00 | 100.00 |
|-----------------+---------+---------|
All looks good, so let’s move on to looking at how to prune our search space.
The Prune Function
If you recall how I constructed the search, it followed a three step process:
(-> the-graph
(expand start-node)
(prune-paths prune?)
(check-complete complete?))
Now I’ve got (expand ...) out of the way, it’s time to look at (prune-paths ...). This is fairly simple to implement, since it is basically just a
(filter ...) on the paths resulting from the (expand ...). If you look
back earlier in this article, I already have a placeholder version of the
function:
(defn prune-paths
[paths prune?]
(filter prune? paths))
It uses a passed in (prune? ...) function, to filter down the passed in set
of paths to just those we are interested in. Consider the question I used
earlier, based on our test graph — “find all routes starting from A and
ending at C, with a length of less than 5”. Here, our (prune? ...) function
would be:
(fn [path] (< (:distance path) 5))
Using this function, the (filter ...) would only keep values for which this
function was true. So any paths which are longer than this will be discarded.
Let’s create a test to represent what I want:
(deftest check-pruning
(testing "Check paths are pruned correctly"
(let [prune? (fn [path] (< (:distance path) 5))
inputs [{:path [:a :b] :distance 1}
{:path [:a :b :c] :distance 3 :complete? true}
{:path [:a :b :c :d] :distance 5 :complete? true}
{:path [:a :b :c :d :e] :distance 7}]
outputs [{:path [:a :b] :distance 1}
{:path [:a :b :c] :distance 3 :complete? true}]]
(is (= (prune-paths inputs prune?)
outputs)))))
Note that I’m allowing pruning of completed paths too. This is because I would not expect this situation to arise. It’s easy to add in a check to prevent this, but I don’t think it is worth doing for the problems I am trying to solve here.
If I run a quick test against my placeholder version of the prune function, it passes:
$ lein test :only kiwiland.search-test/check-pruning
lein test kiwiland.search-test
Ran 1 tests containing 1 assertions.
0 failures, 0 errors.
So actually, my placeholder is good enough to be the final version of this function.
The Check Complete Function
Moving on to the final step of my (search ...) function, here’s the
placeholder (check-complete ...) function I had earlier:
(defn check-complete
[paths complete?]
(map complete? paths))
Again, think of our example question — “find all routes starting from A and
ending at C, with a length of less than 5”. In this case, our (complete? ...) function will need to check that we’ve reached node C, which would look
like this:
(fn [path] (= (-> path :path last) :C))
My placeholder function this time is overly simplistic, I need to change the
(map ...) to check for completeness, and set a flag if the condition is true
(otherwise, do nothing):
(map #(cond (complete? %) (assoc % :complete? true)
:else %)
paths)
Whilst this is fine functionally, it will keep (pointlessly) marking a path as completed — even if it is already marked as complete. I’ll add in a check for that too:
(map #(cond (:complete? %) %
(complete? %) (assoc % :complete? true)
:else %)
paths)
The final thing to remember is that my (expand ...) function doesn’t expand
completed paths. This might be okay for some scenarios, but I’ve already
discussed that some solutions will go through the finish point multiple times.
So, every time I mark a path as complete, I also want to create an uncompleted
copy to be used for expanding. Don’t worry about it expanding forever, Our
prune function will clean it up once it hits the limit we are interested in.
Adding that in, I get the following:
(map #(cond (:complete? %) %
(complete? %) (vector (assoc % :complete? true) %)
:else %)
paths)
Putting this into our placeholder function gives me:
(defn check-complete
[paths complete?]
(map #(cond (:complete? %) %
(complete? %) (vector (assoc % :complete? true) %)
:else %)
paths))
I need to do one more thing in here. I’m using (vector ...) inside a (map ...), so I end up with a list of lists, which I don’t want. So I need to add
a (flatten ...) at the end:
(defn check-complete
[paths complete?]
(-> (map #(cond (:complete? %) %
(complete? %) (vector (assoc % :complete? true) %)
:else %)
paths)
flatten))
So, I’ll create a test which checks a correct completion, an existing completion, and something which shouldn’t complete:
(deftest check-complete
(testing "Check completions are correctly identified"
(let [complete? (fn [path] (= (-> path :path last) :c))
inputs [{:path [:a :b] :distance 1}
{:path [:a :b :c] :distance 2 :complete? true}
{:path [:a :b :c :d] :distance 3}
{:path [:a :b :c :d :c] :distance 4}]
outputs [{:path [:a :b] :distance 1}
{:path [:a :b :c] :distance 2 :complete? true}
{:path [:a :b :c :d] :distance 3}
{:path [:a :b :c :d :c] :distance 4 :complete? true}
{:path [:a :b :c :d :c] :distance 4}]]
(is (= (check-complete inputs complete?)
outputs)))))
And we’re all good:
$ lein test :only kiwiland.search-test/check-complete
lein test kiwiland.search-test
Ran 1 tests containing 1 assertions.
0 failures, 0 errors.
Putting It All Together
Now I have all my parts, let’s go back to the search function I originally thought of, and see how all the parts fit together:
(defn search
[the-graph start-node complete? prune?]
(-> the-graph
(expand start-node)
(prune-paths prune?)
(check-complete complete?)))
The obvious problem is that my envisaged (expand ...) function expects a
node, but the one I actually wrote expects an array of paths. So, I need to
change the function slightly to handle that. This is simple to do — if I get
passed a node, I’ll just create a path consisting of only the start node, and
use that instead:
(defn search
[the-graph the-start complete? prune?]
(let [paths (cond (keyword? the-start) [{:path [the-start]}]
:else the-start)]
(-> the-graph
(expand paths)
(prune-paths prune?)
(check-complete complete?))))
Let’s fire up the REPL, and see what happens. I’ll use it to solve the example question from earlier — “find all routes starting from A and ending at C, with a length of less than 5”:
kiwiland.core=> (require '[kiwiland.search :as search])
nil
kiwiland.core=> (def test-graph (graph/build-graph ["ab1" "bc1" "cb1" "bd1" "dc1"]))
#'kiwiland.core/test-graph
kiwiland.core=> (search/search test-graph :a #(= (-> % :path last) :c) #(< (-> % :distance) 5))
({:path [:a :b], :distance 1})
As far as it goes, this seems fine … it has extended the path by one node, and put in the distance. It looks correct, but not very interesting. Let’s take this result, and feed it back into the function and see what happens:
kiwiland.core=> (search/search test-graph
[{:path [:a :b] :distance 1}]
#(= (-> % :path last) :c) #(< (-> % :distance) 5))
({:path [:a :b :c], :complete? true, :distance 2}
{:path [:a :b :c], :distance 2}
{:path [:a :b :d], :distance 2})
In this case, it has moved on to find the path A -> B -> C and marked it as
complete, it has created a copy of that path to use for further searching, and
it has also found a path A-> B -> D, which is not complete. It has also
correctly increased the distance for each path. What I now need to do, is make
it take these additional steps automatically. I’ll add in a recursive step at
the end of the function to do this.
First thing I need is to know when to stop recursing. This will be when every path in my search space is complete. So here’s a function to achieve that:
(defn all-paths-are-complete?
"Check whether all paths have been marked as complete"
[paths]
(empty? (remove #(:complete? %) paths)))
Now I can modify my search function to call itself if there are still incomplete paths to explore:
(defn search
[the-graph the-start complete? prune?]
(let [paths (cond (keyword? the-start) [{:path [the-start]}]
:else the-start)
expanded-paths (-> the-graph
(expand paths)
(prune-paths prune?)
(check-complete complete?))]
(cond (all-paths-are-complete? expanded-paths) expanded-paths
:else (search the-graph expanded-paths complete? prune?))))
Looking back at our test graph, what solutions do we have to our question? A -> B -> C is an obvious answer. A -> B -> D -> C is another. We are
allowed to repeat stops, so A -> B -> C -> D -> C is also valid. Any other
routes will take us over our less than 5 condition. So, we have our test:
(deftest check-search
(testing "Testing the top-level search function"
(is (= (search test-graph :a #(= (-> % :path last) :c) #(< (-> % :distance) 5))
[{:path [:a :b :c], :complete? true, :distance 2}
{:path [:a :b :c :b :c], :complete? true, :distance 4}
{:path [:a :b :d :c], :complete? true, :distance 3}]))))
Stepping through what happens when we run the function, it starts off by
following the single route from :A which goes to :B:
[{:path [:a :b], :distance 1}]
From :B, there are two possible routes — to :C and to :D. These both
get followed, but the route :A -> :B -> :C is detected as complete and marked
as such:
[{:path [:a :b :c], :complete? true, :distance 2}
{:path [:a :b :c], :distance 2}
{:path [:a :b :d], :distance 2}]
We now have two paths to follow. From :C, there is only one option … going
back to :B. From :D there is also only one option … going on to :C.
Both these paths are extended. In doing so, A -> B -> D -> C is detected as
meeting the completion test, so is duplicated and marked as complete:
[{:path [:a :b :c], :complete? true, :distance 2}
{:path [:a :b :c :b], :distance 3}
{:path [:a :b :d :c], :complete? true, :distance 3}
{:path [:a :b :d :c], :distance 3}]
We go on another step, and find another valid path, A -> B -> C -> B -> C:
[{:path [:a :b :c], :complete? true, :distance 2}
{:path [:a :b :c :b :c], :complete? true, :distance 4}
{:path [:a :b :c :b :c], :distance 4}
{:path [:a :b :c :b :d], :distance 4}
{:path [:a :b :d :c], :complete? true, :distance 3}
{:path [:a :b :d :c :b], :distance 4}]
Note that in the above step, all the paths which are not marked as complete, are all have a length of 4. So when we do our next step, they all become length 5. This means they are all pruned out, leaving us with just the completed paths:
[{:path [:a :b :c], :complete? true, :distance 2}
{:path [:a :b :c :b :c], :complete? true, :distance 4}
{:path [:a :b :d :c], :complete? true, :distance 3}]
Since all our paths are now complete, the function will stop recursing, and returns the above as its result.
One final comment about the recursion. Because of the way I’ve constructed the
function, I can use tail recursion to optimise the recursive step (and use
less memory). To do that, I replace the recursive call to (search ...) with
the function (recur ...):
(defn search
[the-graph the-start complete? prune?]
(let [paths (cond (keyword? the-start) [{:path [the-start]}]
:else the-start)
expanded-paths (-> the-graph
(expand paths)
(prune-paths prune?)
(check-complete complete?))]
(cond (all-paths-are-complete? expanded-paths) expanded-paths
:else (recur the-graph expanded-paths complete? prune?))))
Now we’ve got the search function, I can go back to the original problem and use it.
Back to the Original Problem
So, the first thing I need is to be able to access the search function directly from the graph package, so I’ll include the search namespace into the graph one:
(ns kiwiland.graph
(:require [clojure.string :as str])
(:require [kiwiland.search :as bfsearch]))
Then I’ll make the search function available externally:
(def search bfsearch/search)
To make sure nobody breaks this construct, I’ll add my search test to the graph namespace too:
(def test-graph (build-graph ["ab1" "bc1" "cb1" "bd1" "dc1"]))
(deftest check-search
(testing "Testing the imported search function"
(is (= (search test-graph :a #(= (-> % :path last) :c) #(< (-> % :distance) 5))
[{:path [:a :b :c], :complete? true, :distance 2}
{:path [:a :b :c :b :c], :complete? true, :distance 4}
{:path [:a :b :d :c], :complete? true, :distance 3}]))))
Now let’s think about how to structure our questions:
- The number of trips starting at C and ending at C with a maximum of 3 stops.
- The number of trips starting at A and ending at C with exactly 4 stops.
- The number of different routes from C to C with a distance of less than 30.
We want to pass a start node, a finish condition, and a pruning condition. I think that something like this is a readable way of doing that:
(number-of-trips :C [last = :C] [:stops <= 3])
For a full solution, I would probably use a macro for this, but for now I will simply write a function which parses the complete and parse expressions, and returns the appropriate function for each, then pass these into my search. To do this for the complete expression, I am just shuffling round the terms. Here’s the basic way I will do this:
(defn parse-complete
"Take the expression representing a complete condition, and generate the
appropriate function from it."
[complete-expr]
(let [expr (nth complete-expr 0)
op (nth complete-expr 1)
value (nth complete-expr 2)
value-to-test (-> path :path expr)]
(fn [path]
(op value-to-test value))))
If I use parameter decomposition, and inline the value-to-test derivation, I
get a more concise version:
(defn parse-complete
"Take the expression representing a complete condition, and generate the
appropriate function from it."
[[expr op value]]
(fn [path]
(op (-> path :path expr) value)))
To test this, I decided to do the parsing, and then test against the generated function (rather than trying to analyse the generated function itself):
(deftest check-completion-parser
(testing "The completion parser"
(is (= ((parse-complete [last = :B]) {:path [:A :B]})
true))
(is (= ((parse-complete [last = :C]) {:path [:A :B]})
false))))
Parsing the prune expression is very similar. The only catch is that :stops
is not part of the path construct, so I need to derive that:
(defn parse-prune
"Take the expression representing a prune condition, and generate the
appropriate function from it."
[[elem op value]]
(fn [path]
(let [stops (-> path :path count (- 1))
path-with-stops (assoc path :stops stops)]
(op (get path-with-stops elem) value))))
Now I can create a (count-paths ...) function which makes use of the above
two. Note that the question is only interested in the total number of
valid paths, not the paths themselves. So after I do the search, I then apply
a (count ...):
(defn count-paths
"Search through the graph, to find solutions which satisfy the passed
conditions, then return the total."
[the-graph]
(fn [start-node complete-condition prune-condition]
(let [complete? (parse-complete complete-condition)
prune? (parse-prune prune-condition)]
(-> (graph/search the-graph start-node complete? prune?)
count))))
The next question to answer follows a similar pattern:
(number-of-trips :A [fifth = :C] [:stops <= 4])
Note that I am using a (fifth ...) function, when you might expect it to be
fourth, based on the question. This is because my completion condition is
based on the path, which doesn’t include the starting node as a stop. So
the fourth stop, is the fifth element in my path. My only problem here is that
I don’t have a fifth function. But that is easy to write:
(defn fifth
"Get the fifth element of a list"
[l]
(nth l 4))
My final condition uses distance instead of stops, but my function will handle that fine:
(number-of-trips :C [last = :C] [:distance < 30])
All that’s left to do is add these to my (generate-answers ...) function:
(defn generate-answers
"Generate the answers to the Kiwiland Rail test questions"
[graph-string]
(let [g (-> graph-string
(str/split #", *")
(graph/build-graph))
journey-distance (distance g)
number-of-trips (count-paths g)]
(list (journey-distance [:A :B :C])
(journey-distance [:A :D])
(journey-distance [:A :D :C])
(journey-distance [:A :E :B :C :D])
(journey-distance [:A :E :D])
(number-of-trips :C [last = :C] [:stops <= 3])
(number-of-trips :A [fifth = :C] [:stops <= 4])
9 9
(number-of-trips :C [last = :C] [:distance < 30]))))
Now I can run this and inspect the result:
$ lein run
(9 5 13 22 NO SUCH ROUTE 2 3 9 9 7)
Or I can let my tests take care of that for me:
$ lein cloverage
Loading namespaces: (kiwiland.core kiwiland.graph kiwiland.search)
Test namespaces: (kiwiland.core-test kiwiland.graph-test kiwiland.search-test)
Loaded kiwiland.search .
Loaded kiwiland.graph .
Loaded kiwiland.core .
Instrumented namespaces.
Testing kiwiland.core-test
Testing kiwiland.graph-test
Skipping ab11 since it has more than 3 characters
Skipping 1ab could not parse: java.lang.NumberFormatException
Testing kiwiland.search-test
Ran 42 tests containing 48 assertions.
0 failures, 0 errors.
Ran tests.
Writing HTML report to: /usr/src/lein/target/coverage/index.html
|-----------------+---------+---------|
| Namespace | % Forms | % Lines |
|-----------------+---------+---------|
| kiwiland.core | 100.00 | 100.00 |
| kiwiland.graph | 100.00 | 100.00 |
| kiwiland.search | 100.00 | 100.00 |
|-----------------+---------+---------|
| ALL FILES | 100.00 | 100.00 |
|-----------------+---------+---------|
Summary
I have continued the Kiwiland Railway Problem, started in the previous article, looking at how to implement a breadth-first search in Clojure. In the next article, I will look at how to find the shortest route through the graph.
The code I have discussed in this article is available at ianfinch/kiwiland-clojure (commit #f0af …) .